- жµПиІИ: 140893 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еМЧдЇђ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2014-02 ( 17)
- 2013-12 ( 97)
- 2013-11 ( 183)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
жµЕи∞ИSQLiteвАФвАФжµЕжЮРLemon
1гАБж¶Вињ∞
гААгААLemonжШѓдЄАдЄ™LALR(1)жЦЗж≥ХеИЖжЮРеЩ®зФЯжИРеЈ•еЕЈгАВиЩљзДґеЃГжШѓSQLiteдљЬиАЕйТИеѓєSQLiteеЖЩзЪДдЄАдЄ™еИЖжЮРеЩ®зФЯжИРеЈ•еЕЈпЉМдљЖжШѓеЃГдЄОbisonеТМyaccз±їдЉЉпЉМжШѓдЄАдЄ™еПѓдї•зЛђзЂЛдЇОSQLiteдљњзФ®зЪДеЉАжЇРзЪДеИЖжЮРеЩ®зФЯжИРеЈ•еЕЈгАВиАМдЄФеЃГдљњзФ®дЄОyacc(bison)дЄНеРМзЪДиѓ≠ж≥ХиІДеИЩпЉМеПѓдї•еЗПе∞СзЉЦз®ЛжЧґеЗЇзО∞йФЩиѓѓзЪДжЬЇдЉЪгАВLemonжѓФyaccеТМbisonжЫіз≤ЊиЗігАБжЫіењЂпЉМиАМдЄФжШѓеПѓйЗНеЕ•зЪДпЉМдєЯжШѓзЇњз®ЛеЃЙеЕ®зЪДвАФвАФињЩеѓєдЇОжФѓжМБе§ЪзЇњз®ЛзЪДз®ЛеЇПжШѓйЭЮеЄЄйЗНи¶БзЪДгАВ
гААгААLemonзЪДдЄїи¶БеКЯиГље∞±жШѓж†єжНЃдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥Х(CFG)пЉМзФЯжИРжФѓжМБиѓ•жЦЗж≥ХзЪДеИЖжЮРеЩ®гАВз®ЛеЇПзЪДиЊУеЕ•жЦЗдїґжЬЙдЄ§дЄ™пЉЪ
гААгАА(1)иѓ≠ж≥ХиІДеИЩжЦЗдїґпЉЫ
гААгАА(2)еИЖжЮРеЩ®ж®°жЭњжЦЗдїґгАВ
гААгААдЄАиИђжЭ•иѓіпЉМиѓ≠ж≥ХиІДеИЩжШѓзФ±з®ЛеЇПеСШеЃЪдєЙзЪДпЉЫLemonжЬЙдЄАдЄ™йАВзФ®дЇОе§Іе§ЪжХ∞еЇФзФ®з®ЛеЇПзЪДйїШиЃ§еИЖжЮРеЩ®ж®°жЭњгАВж†єжНЃеСљдї§и°МйАЙй°єпЉМLemonдЉЪзФЯжИРдї•дЄЛдЄАдЇЫжЦЗдїґпЉЪ
гААгАА(1)еИЖжЮРеЩ®зЪДCдї£з†БпЉЫ
гААгАА(2)дЄАдЄ™дЄЇжѓПдЄ™зїИзїУзђ¶еЃЪдєЙдЄАдЄ™жХіеЮЛIDзЪДе§іжЦЗдїґпЉЫ
гААгАА(3)дЄАдЄ™жППињ∞еИЖжЮРеЩ®зКґжАБзЪДжЦЗдїґгАВ
гААгААиѓ≠ж≥ХиІДиМГжЦЗдїґдї•вАЭ.yвАЭдЄЇеРОзЉАпЉМе¶ВжЮЬиѓ≠ж≥ХиІДиМГжЦЗдїґдЄЇвАЭgram.yвАЭпЉМеИЩеПѓдї•дљњзФ®е¶ВдЄЛеСљдї§зФЯжИРеИЖжЮРеЩ®пЉЪ
гААгААlemon gram.y
1.1гАБеИЖжЮРеЩ®жО•еП£
гААгААLemonдЄНдЉЪзФЯжИРдЄАдЄ™еЃМжХізЪДгАБеПѓдї•ињРи°МзЪДз®ЛеЇПгАВеЃГдїЕдїЕзФЯжИРдЄАдЇЫеЃЮзО∞еИЖжЮРеЩ®зЪДе≠РдЊЛз®ЛпЉМзДґеРОзФ±зФ®жИЈз®ЛеЇПеЬ®йАВељУзЪДеЬ∞жЦєи∞ГзФ®ињЩдЇЫе≠РдЊЛз®ЛпЉМдїОиАМзФЯжИРдЄАдЄ™еЃМжХізЪДеИЖжЮРеЩ®гАВ
1.1.1гАБParseAlloc
гААгААз®ЛеЇПеЬ®дљњзФ®LemonзФЯжИРзЪДеИЖжЮРеЩ®дєЛеЙНпЉМењЕй°їеИЫеїЇдЄАдЄ™еИЖжЮРеЩ®гАВе¶ВдЄЛпЉЪ
ParseAllocдЄЇеИЖжЮРеЩ®еИЖйЕНз©ЇйЧіпЉМзДґеРОеИЭеІЛеМЦеЃГпЉМињФеЫЮдЄАдЄ™жМЗеРСеИЖжЮРеЩ®зЪДжМЗйТИгАВSQLiteеѓєеЇФзЪДеЗљжХ∞дЄЇпЉЪ
еЗљжХ∞зЪДеПВжХ∞дЄЇдЄАдЄ™еЗљжХ∞жМЗйТИпЉМеєґеЬ®еЗљжХ∞еЖЕи∞ГзФ®иѓ•жМЗйТИжМЗеРСзЪДеЗљжХ∞гАВе¶ВпЉЪ

 дї£з†Б
дї£з†Б
yyParser*pParser;
pParser=(yyParser*)(*mallocProc)((size_t)sizeof(yyParser));
if(pParser){
pParser->yyidx=-1;
#ifdefYYTRACKMAXSTACKDEPTH
pParser->yyidxMax=0;
#endif
#ifYYSTACKDEPTH<=0
pParser->yystack=NULL;
pParser->yystksz=0;
yyGrowStack(pParser);
#endif
}
returnpParser;
}
1.1.2гАБParseFree
ељУз®ЛеЇПдЄНеЖНдљњзФ®еИЖжЮРеЩ®жЧґпЉМеЇФиѓ•еЫЮжФґдЄЇеЕґеИЖйЕНзЪДеЖЕе≠ШгАВе¶ВдЄЛпЉЪ
SQLiteеѓєеЇФзЪДеЗљжХ∞е¶ВдЄЛпЉЪ
дї£з†Б
void*p,/*Theparsertobedeleted*/
void(*freeProc)(void*)/*Functionusedtoreclaimmemory*/
){
yyParser*pParser=(yyParser*)p;
if(pParser==0)return;
while(pParser->yyidx>=0)yy_pop_parser_stack(pParser);
#ifYYSTACKDEPTH<=0
free(pParser->yystack);
#endif
(*freeProc)((void*)pParser);
}
1.1.3гАБParse
ParseжШѓLemonзФЯжИРзЪДеИЖжЮРеЩ®зЪДж†ЄењГдЊЛз®ЛгАВеЬ®еИЖжЮРеЩ®и∞ГзФ®ParseAllocеРОпЉМеИЖиѓНеЩ®е∞±еПѓдї•е∞ЖеИЗеИЖзЪДиѓНдЉ†йАТзїЩParseпЉМињЫи°Миѓ≠ж≥ХеИЖжЮРгАВSQLiteеѓєеЇФзЪДеЗљжХ∞е¶ВдЄЛпЉЪ
дї£
void*yyp,/*Theparser*/
intyymajor,/*Themajortokencodenumber*/
sqlite3ParserTOKENTYPEyyminor/*Thevalueforthetoken*/
sqlite3ParserARG_PDECL/*Optional%extra_argumentparameter*/
)
иѓ•еЗљжХ∞зФ±sqlite3RunParserи∞ГзФ®пЉЪ
int sqlite3RunParser(Parse *pParse, const char *zSql, char **pzErrMsg)
гААгААsqlite3RunParserдљНдЇОtoken.cжЦЗдїґдЄ≠пЉМеЃГжШѓињЫи°МSQLиѓ≠еП•еИЖжЮРзЪДеЕ•еП£пЉМеЃГи∞ГзФ®sqlite3GetTokenеѓєSQLиѓ≠еП•zSqlињЫи°МеИЖиѓНпЉМзДґеРОи∞ГзФ®sqlite3ParserињЫи°Миѓ≠ж≥ХеИЖжЮРгАВиАМsqlite3ParserеЬ®иѓ≠ж≥ХиІДеИЩеПСзФЯиІДзЇ¶жЧґи∞ГзФ®зЫЄеЇФзЪДopcodeзФЯжИРе≠РдЊЛз®ЛпЉМзФЯжИРopcodeгАВ
1.2гАБдЄОyaccеТМbisonзЪДдЄНеРМдєЛе§Д
LemonдЄОyaccеТМbisonжЬЙдЄАдЇЫдЄНеРМзЪДеЬ∞жЦєпЉЪ
(1)еЬ®yaccеТМbisonдЄ≠пЉМжШѓеИЖжЮРеЩ®и∞ГзФ®еИЖиѓНеЩ®гАВеЬ®LemonпЉМеИЖиѓНеЩ®и∞ГзФ®еИЖжЮРеЩ®пЉЫ
(2)LemonдЄНдЉЪдљњзФ®еЕ®е±АеПШйЗПгАВиАМyaccдЄОbisonеЬ®еИЖжЮРеЩ®дЄОеИЖиѓНеЩ®дєЛйЧідљњзФ®еЕ®е±АеПШйЗПпЉЫ
(3)LemonеЕБиЃЄе§ЪдЄ™еИЖжЮРеЩ®еРМжЧґињРи°МпЉМеЫ†дЄЇеЃГжШѓеПѓйЗНеЕ•зЪДгАВиАМyaccдЄОbisonеНідЄНи°МгАВ
2гАБиЊУеЕ•жЦЗдїґиѓ≠ж≥Х
гААгААLemonзЪДиѓ≠ж≥ХиІДеИЩжЦЗдїґ(grammar specification file)дЄїи¶БзФ®дЇОдЄЇеИЖжЮРеЩ®еЃЪдєЙиѓ≠ж≥ХиІДеИЩгАВж≠§е§ЦпЉМиЊУеЕ•жЦЗдїґињШеМЕжЛђеЕґеЃГдЄАдЇЫжЬЙзФ®зЪДдњ°жБѓпЉМдљњзФ®зЪДLemonзЪДе§ІйГ®еИЖеЈ•дљЬе∞±жШѓеЖЩиѓ≠ж≥ХжЦЗдїґгАВ
2.1гАБзїИзїУзђ¶дЄОйЭЮзїИзїУзђ¶(Terminals and Nonterminals)
гААгААзїИзїУзђ¶йАЪеЄЄжШѓе§ІеЖЩзЪДе≠Чзђ¶дЄ≤(жХ∞е≠ЧжИЦе≠ЧжѓН)гАВйЭЮзїИзїУзђ¶жШѓе∞ПеЖЩзЪДе≠Чзђ¶дЄ≤(жХ∞е≠ЧжИЦе≠ЧжѓН)гАВ
2.2гАБиѓ≠ж≥ХиІДеИЩ(Grammar Rules)
гААгААжѓПдЄ™иѓ≠ж≥ХиІДеИЩзФ±дЄЙйГ®еИЖжЮДжИРпЉЪдї•йЭЮзїИзїУзђ¶еЉАеІЛпЉМйЪПеРОзіІжО•зЭАдЄЇвАЬ::=вАЭпЉМзДґеРОжШѓзїИзїУзђ¶(жИЦйЭЮзїИзїУ)еИЧи°®пЉМиІДеИЩдї•иЛ±жЦЗиѓ≠еП•вАЬ.вАЭзїУе∞ЊгАВе¶ВдЄЛпЉЪ
expr::=exprTIMESexpr.
expr::=LPARENexprRPAREN.
expr::=VALUE.
гААгААдЄКдЊЛдЄ≠пЉМжЬЙдЄАдЄ™йЭЮзїИзїУзђ¶вАЬexprвАЭпЉМеТМ5дЄ™зїИзїУзђ¶пЉЪвАЬPLUSвАЭгАБвАЬTIMESвАЭгАБвАЬLPARENвАЭгАБвАЬRPARENвАЭгАБеТМвАЬVALUEвАЭгАВ
дЄОyaccеТМbisonдЄАж†ЈпЉМLemonеЕБиЃЄдЄЇиІДеИЩжЈїеК†Cдї£з†БеЭЧпЉМеєґзФ±еИЖжЮРеЩ®ињЫи°МиІДеИЩиІДзЇ¶жЧґи∞ГзФ®гАВе¶ВдЄЛпЉЪ
expr ::= expr PLUS expr. { printf("Doing an addition...\n"); }
гААгААдЄЇдЇЖдљњиІДеИЩжЬЙзФ®пЉМиѓ≠ж≥ХеК®дљЬ(grammar actions)ењЕй°їдЄОзЫЄеЇФзЪДиѓ≠ж≥ХиІДеИЩиБФз≥їиµЈжЭ•гАВеЬ®yaccеТМbisonдЄ≠пЉМеК®дљЬ(action)дЄ≠зЪДвАЬ$$вАЭдї£и°®еЈ¶еАЉпЉМиАМвАЬ$1вАЭгАБвАЬ$2вАЭз≠ЙеИЩдї£и°®вАЬ::=вАЭеП≥иЊєзЪДдљНзљЃзЫЄеЇФдЄЇ1гАБ2з≠ЙзЪДзїИзїУзђ¶жИЦйЭЮзїИзїУзђ¶зЪДеАЉгАВињЩжШѓйЭЮеЄЄжЬЙзФ®зЪДпЉМдљЖжШѓпЉМеНійЭЮеЄЄеЃєжШУеЗЇйФЩгАВдЊЛе¶ВпЉЪ
expr -> expr PLUS expr { $$ = $1 + $3; };
гААгААиАМLemonйАЪињЗдЄЇиІДеИЩдЄ≠зЪДжѓПдЄ™зђ¶еПЈжМЗеЃЪдЄАдЄ™йҐЭе§ЦзЪДзђ¶еПЈеРНе≠Ч(symbolic)иЊЊеИ∞зЫЄеРМзЪДзЫЃзЪДпЉМзДґеРОеЬ®еК®дљЬдЄ≠дљњзФ®ињЩдЇЫзђ¶еПЈеРНе≠ЧгАВе¶ВдЄЛпЉЪ
expr(A) ::= expr(B) PLUS expr(C). { A = B+C; }
2.3гАБдЉШеЕИзЇІиІДеИЩ(Precedence Rules)
LemonйЗЗзФ®дЄОyaccеТМbisonзЫЄеРМзЪДжЦєж≥Хе§ДзРЖж≠ІдєЙжАІйЧЃйҐШгАВзІїињЫвАФиІДзЇ¶еЖ≤з™БпЉМеИЩйАЙжЛ©зІїињЫпЉЫиІДзЇ¶вАФвАФиІДзЇ¶еЖ≤з™БпЉМеИЩйАЙжЛ©еЕИеЗЇзО∞зЪДиІДеИЩгАВ
еРМж†ЈпЉМLemonдєЯеЕБиЃЄйАЪињЗдЉШеЕИзЇІиІДеИЩжЭ•иІ£еЖ≥еЖ≤з™БгАВе¶ВдЄЛпЉЪ
%left AND.
%left OR.
%nonassoc EQ NE GT GE LT LE.
%left PLUS MINUS.
%left TIMES DIVIDE MOD.
%right EXP NOT.
2.4гАБзЙєжЃКжМЗз§Їзђ¶(Special Directives)
LemonжФѓжМБе¶ВдЄЛдЄАдЇЫзЙєжЃКжМЗз§Їзђ¶пЉЪ
дї£з†Б
%default_destructor
%default_type
%destructor
%extra_argument
%include
%left
%name
%nonassoc
%parse_accept
%parse_failure
%right
%stack_overflow
%stack_size
%start_symbol
%syntax_error
%token_destructor
%token_prefix
%token_type
%type
пБђ%code
%codeи°®з§Їе∞ЖдЄАжЃµC/C++дї£з†БжЈїеК†еИ∞иЊУеЗЇжЦЗдїґзЪДе∞ЊйГ®гАВеЃГдЄїи¶БзФ®дЇОеМЕеРЂдЄАдЇЫеК®дљЬдЊЛз®Л(action routines)жИЦиАЕиѓНж≥ХеЩ®зЪДйГ®еИЖдї£з†БгАВ
пБђ%default_type
е¶ВжЮЬж≤°жЬЙеЬ®%typeдЄ≠дЄЇйЭЮзїИзїУзђ¶жМЗеЃЪжХ∞жНЃз±їеЮЛпЉМеИЩdefault_typeжМЗеЃЪйЭЮзїИзїУзђ¶зЪДжХ∞жНЃз±їеЮЛгАВ
пБђ%destructor
дЄЇйЭЮзїИзїУзђ¶жМЗеЃЪдЄАдЄ™иµДжЇРйЗКжФЊеЩ®(destructor)пЉИ%token_destructorдЄЇзїИзїУзђ¶жМЗеЃЪиµДжЇРйЗКжФЊеЩ®пЉЙгАВељУйЭЮзїИзїУзђ¶дїОеИЖжЮРж†ИдЄ≠еЉєеЗЇжЧґпЉМйЗКжФЊеЩ®е∞±дЉЪ襀и∞ГзФ®пЉМдї•йЗКжФЊеЕґеН†зФ®зЪДиµДжЇРгАВеМЕжЛђе¶ВдЄЛжГЕеЖµпЉЪ
(1)дЄАдЄ™иІДеИЩеПСзФЯиІДзЇ¶пЉМиАМйЭЮзїИзїУзђ¶зЪДеП≥иЊєеНіж≤°жЬЙCдї£з†БпЉЫ
(2)еЬ®йФЩиѓѓе§ДзРЖдЄ≠пЉМеЗЇж†ИжУНдљЬпЉЫ
(3)ParseFreeеЗљжХ∞ињФеЫЮгАВ
йЗКжФЊеЩ®еПѓдї•еБЪдїїдљХжУНдљЬпЉМдљЖжШѓеЃГдЄїи¶БзФ®жЭ•йЗКжФЊйЭЮзїИзїУзђ¶еН†зФ®зЪДеЖЕе≠ШжИЦеЕґеЃГиµДжЇРгАВдЊЛпЉЪ
%type nt {void*}
%destructor nt { free($$); }
nt(A) ::= ID NUM. { A = malloc( 100 ); }
еЬ®дЊЛе≠РдЄ≠пЉМвАЬntвАЭзЪДжХ∞жНЃз±їеЮЛдЄЇвАЬvoid *вАЭгАВељУвАЬntвАЭзЪДиІДеИЩеПСзФЯиІДзЇ¶жЧґпЉМдЄЇйЭЮзїИзїУзђ¶йАЪињЗmallocеИЖйЕНз©ЇйЧігАВдєЛеРОпЉМељУйЭЮзїИзїУзђ¶дїОж†ИдЄ≠еЉєеЗЇжЧґпЉМйЗКжФЊеЩ®дЉЪ襀и∞ГзФ®пЉМдї•йЗКжФЊmallocзФ≥иѓЈзЪДеЖЕе≠ШгАВињЩеПѓдї•йБњеЕНеЖЕе≠Шж≥ДжЉПгАВ
ж≥®жДПпЉМйЩ§йЭЮйЭЮзїИзїУзђ¶дЉЪеЬ®CеК®дљЬдї£з†БдЄ≠дљњзФ®пЉМеР¶еИЩпЉМељУйЭЮзїИзїУзђ¶дїОж†ИдЄ≠еЉєеЗЇжЧґпЉМе∞±дЉЪи∞ГзФ®йЗКжФЊеЩ®йЗКжФЊиµДжЇРгАВе¶ВжЮЬCдї£з†БдљњзФ®йЭЮзїИзїУзђ¶пЉМеИЩзФ±Cдї£з†БдњЭиѓБиµДжЇРзЪДйЗКжФЊгАВ
пБђ%token_prefix
LemonзЪДзФЯжИРжЦЗдїґдЉЪдЄЇжѓПдЄ™зїИзїУзђ¶еЃЪдєЙдЄАдЄ™жХіжХ∞еАЉгАВе¶ВдЄЛпЉЪ
#define AND 1
#define MINUS 2
#define OR 3
#define PLUS 4
е¶ВжЮЬжДњжДПпЉМеПѓдї•йАЪињЗиѓ•жМЗз§Їзђ¶дЄЇ#defineзЪДйҐДе§ДзРЖзђ¶еПЈеК†дЄАдЄ™еЙНзЉАгАВдЊЛе¶ВпЉМеПѓдї•еЬ®иІДеИЩжЦЗдїґеК†дЄКе¶ВдЄЛпЉЪ
%token_prefix TOKEN_
еИЩзФЯжИРзЪДжЦЗдїґзЪДиЊУеЗЇе¶ВдЄЛпЉЪ
#define TOKEN_AND 1
#define TOKEN_MINUS 2
#define TOKEN_OR 3
#define TOKEN_PLUS 4
пБђ%include
зФ±иѓ•жМЗз§Їзђ¶жМЗеЃЪзЪДCдї£з†БдЉЪеМЕеРЂеИ∞зФЯжИРзЪДеИЖжЮРзЪДй°ґйГ®гАВдљ†еПѓдї•еМЕеРЂдїїжДПдї£з†БпЉМLemonдЉЪеЃМеЕ®жЛЈиіЭињЗеОїгАВ
пБђ%extra_argument
жМЗз§ЇParseеЗљжХ∞дЄ≠зђђеЫЫдЄ™еПВжХ∞гАВ LemonжЬђиЇЂдЄНдЉЪеБЪдїїдљХе§ДзРЖпЉМдљЖжШѓзЫЄеЇФзЪДCдї£з†БеПѓдї•дљњзФ®иѓ•еПВжХ∞гАВ
пБђ%parse_accept
еИЖжЮРеЩ®ињЫи°Миѓ≠ж≥ХеИЖжЮРжИРеКЯжЧґпЉМжЙІи°МзЪДCдї£з†БгАВе¶ВпЉЪ
%parse_accept {
printf("parsing complete!\n");
}
пБђ%stack_overflow
ељУеИЖжЮРеЩ®жЙІи°МеПСзФЯеЖЕйГ®ж†ИжЇҐеЗЇжЧґпЉМдЉЪжЙІи°МзЫЄеЇФзЪДеК®дљЬгАВйАЪеЄЄпЉМеПѓдї•иЊУеЗЇйФЩиѓѓжґИжБѓпЉМеИЖжЮРеЩ®дЄНиГљзїІзї≠жЙІи°МпЉМиАМењЕй°їйЗНзљЃгАВдЊЛе¶ВпЉЪ
%stack_overflow {
fprintf(stderr,"Giving up. Parser stack overflow\n");
}
пБђ%name
йїШиЃ§жГЕеЖµдЄЛпЉМLemonзФЯжИРзЪДеЗљжХ∞йГљдї•вАЬParseвАЭеЉАеІЛпЉМеПѓдї•йАЪињЗиѓ•жМЗз§Їзђ¶дњЃжФєгАВдЊЛе¶ВпЉЪ
%name Abcde
ињЩдЉЪеѓЉиЗіLemonзФЯжИРзЪДеЗљжХ∞зЪДеРНе≠Че¶ВдЄЛпЉЪ
AbcdeAlloc(),
AbcdeFree(),
AbcdeTrace(), and
Abcde().
пБђ%token_typeдЄО%type
ињЩдЇЫжМЗз§Їзђ¶зФ®дЇОдЄЇеИЖжЮРеЩ®зЪДж†ИдЄ≠зЪДзїИзїУзђ¶жИЦйЭЮзїИзїУжМЗеЃЪжХ∞жНЃз±їеЮЛгАВжЙАжЬЙзїИзїУзђ¶йГљењЕй°їжШѓзЫЄеРМзЪДз±їеЮЛпЉМиАМдЄОеЇФиѓ•дЄОLemonзФЯжИРзЪДиЊУеЗЇжЦЗдїґдЄ≠зЪДParse()зЪДзђђ3дЄ™еПВжХ∞зЪДз±їеЮЛдЄАиЗігАВйАЪеЄЄпЉМеПѓдї•е∞ЖдЄАдЄ™зїУжЮДжМЗйТИиµЛзїЩзїИзїУзђ¶пЉМе¶ВдЄЛпЉЪ
%token_type {Token*}
е¶ВжЮЬзїИзїУзђ¶зЪДжХ∞жНЃз±їеЮЛж≤°жЬЙжМЗеЃЪпЉМйїШиЃ§дЄЇвАЬintвАЭгАВ
йАЪеЄЄпЉМжѓПдЄ™йЭЮзїИзїУзђ¶йГљжЬЙеРДиЗ™зЪДжХ∞жНЃз±їеЮЛгАВдЊЛе¶ВпЉМйАЪеЄЄйЭЮзїИзїУзђ¶дЄЇжМЗеРСзЪДеИЖжЮРж†СзЪДж†єзїУзВєзЪДжХ∞жНЃз±їеЮЛжМЗйТИпЉМиѓ•ж†єзїУзВєеМЕеРЂйЭЮзїИзїУзђ¶зЪДжЙАжЬЙдњ°жБѓгАВдЊЛе¶ВпЉЪ
%type expr {Expr*}
3гАБSQLiteиѓ≠ж≥ХиІДеИЩеИЖжЮР
гААгААдЄЛйЭҐдї•SELECTиѓ≠еП•зЃАи¶БзЪДж¶Вињ∞дЄАдЄЛSQLiteзЪДиѓ≠ж≥ХиІДеИЩгАВ
3.1гАБSELECTиѓ≠ж≥Х
гААгААSELECTиѓ≠ж≥ХжШѓSQLиѓ≠еП•дЄ≠жЬАе§НжЭВзЪДйГ®еИЖдєЛдЄАгАВиАМеЕґеЃГSQLиѓ≠еП•пЉМжѓФе¶ВCREATEпЉИDROPпЉЙ TABLEгАБCREATEпЉИDROPпЉЙINDEXгАБINSERTгАБDELETEгАБUPDATEзЫЄеѓєжЭ•иѓіжѓФиЊГзЃАеНХгАВ
3.1.1гАБselect-stmt
selectзЪДиѓ≠ж≥ХеЕ®еЫЊпЉЪ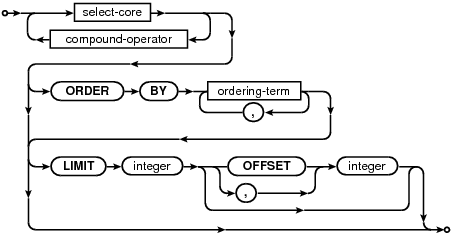
3.1.2гАБselect-core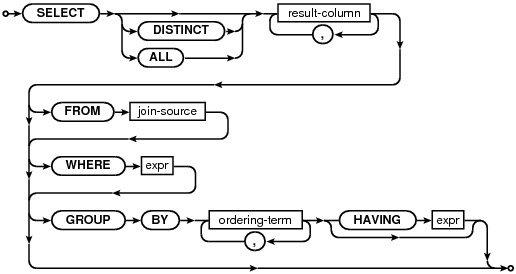
зЫЄеЇФзЪДиѓ≠ж≥ХиІДеИЩпЉЪ
дї£з†Б
SelectDestdest={SRT_Output,0,0,0,0};
sqlite3Select(pParse,X,&dest);
sqlite3SelectDelete(pParse->db,X);
}
%typeselect{Select*}//selectиѓ≠еП•еѓєеЇФзЪДзїУжЮДдљУ
%destructorselect{sqlite3SelectDelete(pParse->db,$$);}
%typeoneselect{Select*}
%destructoroneselect{sqlite3SelectDelete(pParse->db,$$);}
select(A)::=oneselect(X).{A=X;}
//...
//зЃАеНХSQLиѓ≠еП•,еПѓдї•еИЖжИРдї•дЄЛеЗ†йГ®еИЖ:иЊУеЗЇеИЧгАБfromе≠РеП•гАБwhereе≠РеП•гАБgroupе≠РеП•гАБhavingе≠РеП•
oneselect(A)::=SELECTdistinct(D)selcollist(W)from(X)where_opt(Y)
groupby_opt(P)having_opt(Q)orderby_opt(Z)limit_opt(L).{
A=sqlite3SelectNew(pParse,W,X,Y,P,Q,Z,D,L.pLimit,L.pOffset);
}
пБђ
гААгААdistinct
distinct(A)::=DISTINCT.{A=1;}
distinct(A)::=ALL.{A=0;}
distinct(A)::=.{A=0;}
пБђselcollist(иЊУеЗЇзїУжЮЬеИЧ)
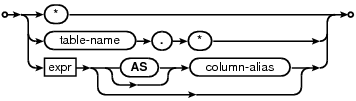
дї£з†Б
%destructorselcollist{sqlite3ExprListDelete(pParse->db,$$);}
%typesclp{ExprList*}
%destructorsclp{sqlite3ExprListDelete(pParse->db,$$);}
sclp(A)::=selcollist(X)COMMA.{A=X;}
sclp(A)::=.{A=0;}
selcollist(A)::=sclp(P)expr(X)as(Y).{
A=sqlite3ExprListAppend(pParse,P,X.pExpr);
if(Y.n>0)sqlite3ExprListSetName(pParse,A,&Y,1);
sqlite3ExprListSetSpan(pParse,A,&X);
}
selcollist(A)::=sclp(P)STAR.{
Expr*p=sqlite3Expr(pParse->db,TK_ALL,0);
A=sqlite3ExprListAppend(pParse,P,p);
}
selcollist(A)::=sclp(P)nm(X)DOTSTAR(Y).{
Expr*pRight=sqlite3PExpr(pParse,TK_ALL,0,0,&Y);
Expr*pLeft=sqlite3PExpr(pParse,TK_ID,0,0,&X);
Expr*pDot=sqlite3PExpr(pParse,TK_DOT,pLeft,pRight,0);
A=sqlite3ExprListAppend(pParse,P,pDot);
}
//Anoption"AS<id>"phrasethatcanfollowoneoftheexpressionsthat
//definetheresultset,oroneofthetablesintheFROMclause.
//ASиѓ≠еП•
%typeas{Token}
as(X)::=ASnm(Y).{X=Y;}
as(X)::=ids(Y).{X=Y;}
as(X)::=.{X.n=0;}
пБђfrom
fromе≠РеП•еИЖдї•дЄЛеЗ†йГ®еИЖпЉЪ
join-sourceпЉЪ
single-sourceпЉЪ

join-opпЉЪ
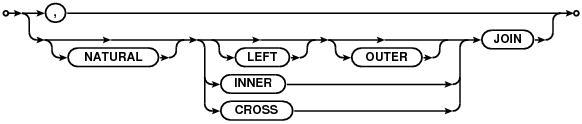
join-constraintпЉЪ
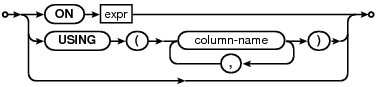
иѓ≠ж≥ХиІДеИЩпЉЪ
дї£з†Б
%destructorseltablist{sqlite3SrcListDelete(pParse->db,$$);}
%typestl_prefix{SrcList*}
%destructorstl_prefix{sqlite3SrcListDelete(pParse->db,$$);}
%typefrom{SrcList*}
%destructorfrom{sqlite3SrcListDelete(pParse->db,$$);}
//AcompleteFROMclause.FROMе≠РеП•
//
from(A)::=.{A=sqlite3DbMallocZero(pParse->db,sizeof(*A));}
from(A)::=FROMseltablist(X).{
A=X;
sqlite3SrcListShiftJoinType(A);
}
//"seltablist"isa"SelectTableList"-thecontentoftheFROMclause
//inaSELECTstatement."stl_prefix"isaprefixofthislist.
//
stl_prefix(A)::=seltablist(X)joinop(Y).{
A=X;
if(ALWAYS(A&&A->nSrc>0))A->a[A->nSrc-1].jointype=(u8)Y;
}
stl_prefix(A)::=.{A=0;}
//fromеРОйЭҐзЪДиѓ≠еП•
seltablist(A)::=stl_prefix(X)nm(Y)dbnm(D)as(Z)indexed_opt(I)on_opt(N)using_opt(U).{
A=sqlite3SrcListAppendFromTerm(pParse,X,&Y,&D,&Z,0,N,U);
sqlite3SrcListIndexedBy(pParse,A,&I);
}
//жХ∞жНЃеЇУеРН
%typedbnm{Token}
dbnm(A)::=.{A.z=0;A.n=0;}
dbnm(A)::=DOTnm(X).{A=X;}
//еЕ®еРН
%typefullname{SrcList*}
%destructorfullname{sqlite3SrcListDelete(pParse->db,$$);}
fullname(A)::=nm(X)dbnm(Y).{A=sqlite3SrcListAppend(pParse->db,0,&X,&Y);}
//joinиѓ≠еП•
%typejoinop{int}
%typejoinop2{int}
joinop(X)::=COMMA|JOIN.{X=JT_INNER;}
joinop(X)::=JOIN_KW(A)JOIN.{X=sqlite3JoinType(pParse,&A,0,0);}
joinop(X)::=JOIN_KW(A)nm(B)JOIN.{X=sqlite3JoinType(pParse,&A,&B,0);}
joinop(X)::=JOIN_KW(A)nm(B)nm(C)JOIN.
{X=sqlite3JoinType(pParse,&A,&B,&C);}
//onиѓ≠еП•
%typeon_opt{Expr*}
%destructoron_opt{sqlite3ExprDelete(pParse->db,$$);}
on_opt(N)::=ONexpr(E).{N=E.pExpr;}
on_opt(N)::=.{N=0;}
//NotethatthisblockabusestheTokentypejustalittle.Ifthereis
//no"INDEXEDBY"clause,thereturnedtokenisempty(z==0&&n==0).If
//thereisanINDEXEDBYclause,thenthetokenispopulatedaspernormal,
//withzpointingtothetokendataandncontainingthenumberofbytes
//inthetoken.
//
//Ifthereisa"NOTINDEXED"clause,then(z==0&&n==1),whichis
//normallyillegal.Thesqlite3SrcListIndexedBy()function
//recognizesandinterpretsthisasaspecialcase.
//indexbyиѓ≠еП•(дЉЉдєОдЄНе±ЮдЇОSQL92ж†ЗеЗЖ)
%typeindexed_opt{Token}
indexed_opt(A)::=.{A.z=0;A.n=0;}
indexed_opt(A)::=INDEXEDBYnm(X).{A=X;}
indexed_opt(A)::=NOTINDEXED.{A.z=0;A.n=1;}
//usingиѓ≠еП•
%typeusing_opt{IdList*}
%destructorusing_opt{sqlite3IdListDelete(pParse->db,$$);}
using_opt(U)::=USINGLPinscollist(L)RP.{U=L;}
using_opt(U)::=.{U=0;}
пБђorder by
дї£з†Б
%destructororderby_opt{sqlite3ExprListDelete(pParse->db,$$);}
%typesortlist{ExprList*}
%destructorsortlist{sqlite3ExprListDelete(pParse->db,$$);}
%typesortitem{Expr*}
%destructorsortitem{sqlite3ExprDelete(pParse->db,$$);}
//orderbyиѓ≠еП•
orderby_opt(A)::=.{A=0;}
orderby_opt(A)::=ORDERBYsortlist(X).{A=X;}
sortlist(A)::=sortlist(X)COMMAsortitem(Y)sortorder(Z).{
A=sqlite3ExprListAppend(pParse,X,Y);
if(A)A->a[A->nExpr-1].sortOrder=(u8)Z;
}
sortlist(A)::=sortitem(Y)sortorder(Z).{
A=sqlite3ExprListAppend(pParse,0,Y);
if(A&&ALWAYS(A->a))A->a[0].sortOrder=(u8)Z;
}
sortitem(A)::=expr(X).{A=X.pExpr;}
//й°ЇеЇП
%typesortorder{int}
sortorder(A)::=ASC.{A=SQLITE_SO_ASC;}
sortorder(A)::=DESC.{A=SQLITE_SO_DESC;}
sortorder(A)::=.{A=SQLITE_SO_ASC;}
пБђgroup by
дї£з†Б
%destructorgroupby_opt{sqlite3ExprListDelete(pParse->db,$$);}
groupby_opt(A)::=.{A=0;}
groupby_opt(A)::=GROUPBYnexprlist(X).{A=X;}
гААгАА
гААгААhaving
%destructorhaving_opt{sqlite3ExprDelete(pParse->db,$$);}
having_opt(A)::=.{A=0;}
having_opt(A)::=HAVINGexpr(X).{A=X.pExpr;}
гААгААlimit
дї£з†Б
//Thedestructorforlimit_optwillneverfireinthecurrentgrammar.
//Thelimit_optnon-terminalonlyoccursattheendofasingleproduction
//ruleforSELECTstatements.Assoonastherulethatcreatethe
//limit_optnon-terminalreduces,theSELECTstatementrulewillalso
//reduce.Sothereisneveralimit_optnon-terminalonthestack
//exceptasatransient.Sothereisneveranythingtodestroy.
//
//%destructorlimit_opt{
//sqlite3ExprDelete(pParse->db,$$.pLimit);
//sqlite3ExprDelete(pParse->db,$$.pOffset);
//}
limit_opt(A)::=.{A.pLimit=0;A.pOffset=0;}
limit_opt(A)::=LIMITexpr(X).{A.pLimit=X.pExpr;A.pOffset=0;}
limit_opt(A)::=LIMITexpr(X)OFFSETexpr(Y).
{A.pLimit=X.pExpr;A.pOffset=Y.pExpr;}
limit_opt(A)::=LIMITexpr(X)COMMAexpr(Y).
{A.pOffset=X.pExpr;A.pLimit=Y.pExpr;}
дЄїи¶БеПВиАГпЉЪ


- 2013-11-26 23:06
- жµПиІИ 380
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
жµЕи∞ИSQLiteжХ∞жНЃеЇУжУНдљЬеЄЄзФ®жЦєж≥Х.docx
AndroidжЇРз†БвАФвАФжХ∞жНЃеЇУSQLite.zip
sqlite_array_query вАФвАФ еПСйАБдЄАжЭ° SQL жߕ胥пЉМеєґињФеЫЮдЄАдЄ™жХ∞зїДгАВ sqlite_busy_timeout вАФвАФ иЃЊзљЃиґЕжЧґжЧґйЧіпЉИbusy timeout durationпЉЙпЉМжИЦиАЕйҐСзєБзЪДзФ®жȣ姱еОїжЭГйЩРпЉИdisable busy handlersпЉЙгАВ sqlite_changes вАФвАФ ињФеЫЮ襀...
SQLiteManagerжШѓдЄАдЄ™жФѓжМБе§ЪеЫљиѓ≠и®АеЯЇдЇОWebзЪДSQLiteжХ∞жНЃеЇУзЃ°зРЖеЈ•еЕЈ.еЃГзЪДзЙєзВєеМЕжЛђе§ЪжХ∞жНЃеЇУзЃ°зРЖ,еИЫеїЇеТМињЮжО•;и°®ж†Љ,жХ∞жНЃ,糥еЉХжУНдљЬ;иІЖеЫЊ,иІ¶еПСеЩ®,еТМиЗ™еЃЪдєЙеЗљжХ∞зЃ°зРЖ.жХ∞жНЃеѓЉеЕ•/еѓЉеЗЇ;жХ∞жНЃеЇУзїУжЮДеѓЉеЗЇ.
жХ∞жНЃеЇУи¶БеБЪиѓЊз®ЛиЃЊиЃ°пЉМжИСе∞±зФ®дЇЖSQLiteжЭ•зО©дЇЖдЄАдЄЛпЉМйАЙйҐШжШѓвАЬе≠¶зФЯдњ°жБѓзЃ°зРЖз≥їзїЯвАЭ psпЉЪеБЪзЪДдЄНе§ЯеЕ®йЭҐпЉМдєЯж≤°жЬЙиАГиЩСиЃЊиЃ°ж®°еЉПзЪДйЧЃйҐШпЉМдїЕдЊЫеПВиАГеУИ
иѓЊе†ВдљЬдЄЪеЃЮй™М6жЇРз†БгАВеИ©зФ®androidзЪДеЖЕзљЃжХ∞жНЃеЇУSQLiteе≠ШеВ®жЦ∞йЧїдњ°жБѓпЉМзФ®listviewзїДдїґдї•еИЧ谮嚥еЉПжШЊз§ЇжЦ∞йЧїеЖЕеЃє,
IOSеЇФзФ®жЇРз†БвАФвАФSQLite.rar
IOSдЄ≠зђђдЄЙжЦєSQLiteжФѓжМБеМЕпЉМеЃЮзО∞еЯЇжЬђзЪДDBжУНдљЬDemo
SQLiteзїГдє†й°єзЫЃвАФвАФиБФз≥їдЇЇеИЧи°®еҐЮеИ†жФєжЯ•пЉМеОЯеНЪеЃҐеЬ∞еЭАhttps://blog.csdn.net/u010356768/article/details/80461429
SQLiteзЪДеЃЮйЩЕеЇФзФ®вАФвАФзЩЊеЇ¶зњїиѓС
еЃЙеНУAndroidжЇРз†БвАФвАФSqliteManagerжЇРз†Б.zip
SQLiteзїГдє†пЉМйАЪињЗжХ∞жНЃеЇУиѓїеПЦйЯ≥дєРеИЧи°® еОЯеНЪеЃҐеЬ∞еЭАhttps://mp.csdn.net/mdeditor/80490042 https://blog.csdn.net/u010356768/article/details/80519268
еЃЙеНУAndroidжЇРз†БвАФвАФжХ∞жНЃеЇУSQLite.zip
ељУйБЗеИ∞svn: E155009: Failed to run the WC DB work queue associated withйФЩиѓѓжЧґйЬАи¶БзФ®еИ∞зЪДSQLiteжХ∞жНЃеЇУжЙУеЉАеЈ•еЕЈгАВж≠§еЈ•еЕЈжШѓ2018.08.15дЄЛиљљзЪДеЃШзљСжЬАжЦ∞зЙИжЬђгАВ
AndroidжЇРз†БвАФвАФињЮжО•SQLiteжХ∞жНЃеЇУжЇРз†Б.zip
еЕЈдљУдљњзФ®еПѓеПВиАГжЦЗзЂ†пЉЪhttp://t.csdn.cn/n54CZ
иѓ•йЩДдїґдЄЇеНЪжЦЗгАКSQLiteзЉЦиѓСеЩ®йГ®еИЖжµЕжЮРгАЛйЩДдїґпЉМеЖЕжґµжЇРз†БгАБзЉЦиѓСеЩ®йГ®еИЖз≠ЙжЇРз†БпЉМеРМжЧґеЖЕйЩДеЃЙи£ЕSQLiteжХЩз®ЛпЉМеПѓйБњеЕНзїЭе§ІйГ®еИЖеЭСпЉМеПѓеѓєзЕІеНЪжЦЗдљњзФ®
жЬђжЦЗдЄїи¶БиЃ≤иІ£SQLiteдЄ≠жЧґйЧіеЗљжХ∞ињЫи°МеИЖжЮРдЄОжАїзїУеєґзїЩеЗЇдљњзФ®ж°ИдЊЛгАВжЬђжЦЗзїЩеЗЇзЪДдЊЛе≠РйГљжШѓзїПињЗжµЛиѓХгАВSQLiteжЧґйЧі/жЧ•жЬЯеЗљжХ∞зІНз±їпЉЪ1гАБdatetime()пЉЪдЇІзФЯжЧ•жЬЯеТМжЧґйЧі2гАБdate()пЉЪдЇІзФЯжЧ•жЬЯ3:гАБtime()пЉЪдЇІзФЯжЧґйЧі4гАБstrftime()пЉЪеѓєдї•дЄК...
AndroidжЇРз†БвАФвАФSqliteManager жЇРз†Б.zip